This Post comes form a mix of having to deal with corporate firewalls that break HTTPS connections for my day job, and because someone mentioned some issues introduced by Russia mandating blocks and how they are implemented.
What’s required to GET content via http#
To figure out what happens when we get some resource via http, let’s do exactly that and look at the network while this happens.
To do this, I set up a fresh ubuntu (24.04.01) live boot and started to listen on the network with tcpdump -s 65535 -w /tmp/google.com.pcap and ran curl http://www.google.com.
To analyze the .pcap file I use wireshark. It’s a great tool for digging deeper into network protocols.
When we open the .pcap file in wireshark, it shows an overview of network activity stored in the file.
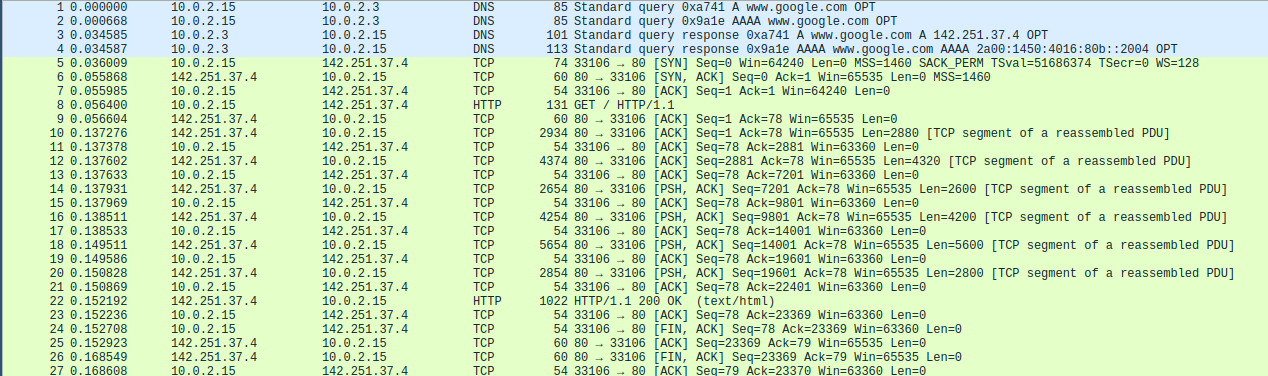
We can see 3 protocols it detected, marked in 2 colours. And with some knowledge, detect 3 streams.
Next, we’ll take a look at what this means. Thankfully, the colour coding of wireshark helps with guiding this analysis.
DNS Request + Response#
First there’s two DNS requests and response pairs marked in blue. Both for www.google.com, one for the A(IPv4) and one for the AAAA(IPv6) entry.
Since the VM only has an IPv4 address, that’s what’s used later on. So let’s take a better look at this exchange. To do this, click on the response request in the overview. It’ll show the decoder in the bottom left.
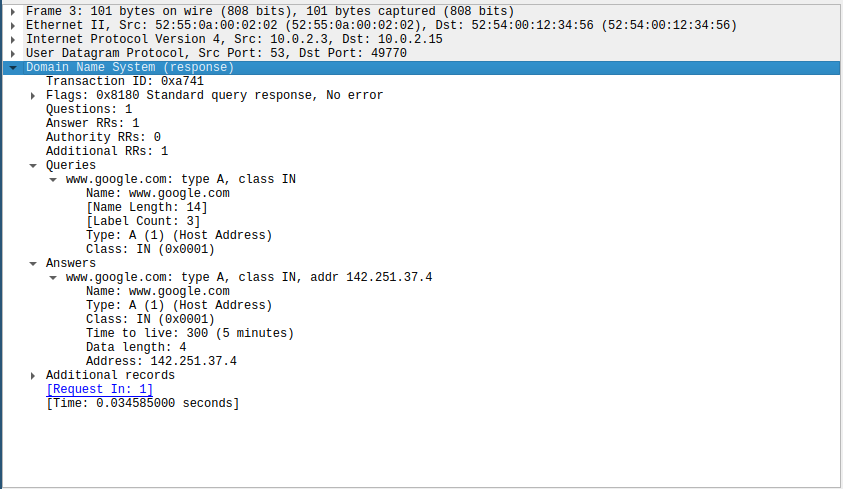
We can see that the request (query in DNS) asked for the A entry of www.google.com. I.e. it wants to know the IPv4 address of www.google.com.
And the response delivers. It’s 142.251.37.4 in this example.
Due to how Google operates, this might be wildly different for you.
Nice, so now we know the first thing that happens when we try to GET www.google.com is a DNS request to convert the name to an IP address.
TCP+HTTP#
The second stream is marked in green, and contains 2 protocols. TCP and HTTP.
TCP#
For the purpose of this article, we can largely ignore TCP. Just know that it allows software to pretend communication happens as one large thing instead of caring about the individual frames we see in wireshark.
HTTP#
To dig deeper into the HTTP stream, right click any frame with http protocol, select Follow and then HTTP Stream.
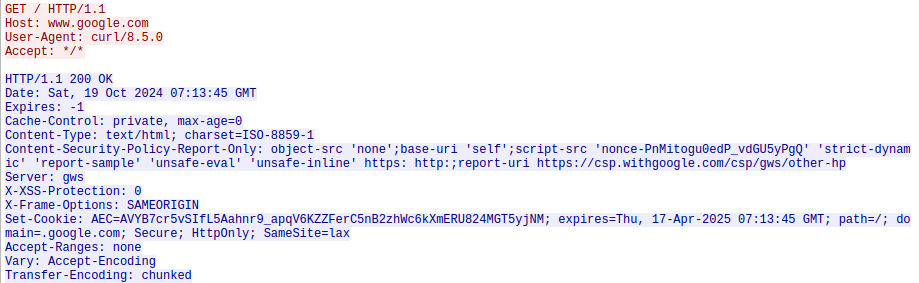
All we are really interested in is the basics of http
GET / HTTP/1.1
Host: www.google.com
User-Agent: curl/8.5.0
Accept: */*
HTTP/1.1 200 OK
The colour coding in wireshark allows us to see that the first block is the request from the client to the server, and then second block is the response form the server.
I this case, it’s a simple HTTP GET request for the resource at / (i.e. the root of the page).
If you look further into the request, there’s the entire content of the page in text.
With this knowledge we can talk about the methods of filtering requests on HTTP.
Interlude: Layers#
This section ties the DNS resolution and the HTTP layer together through the IP and TCP layers in between.
Layer Model#
While the 7 Layer model is probably best known, I prefer the 4 Layer. IMO this works better for describing real network streams “as viewed by the network”, while the 7 layer model can work better for looking at the structure from a software endpoint perspective.
Link Layer#
We can largely ignore the link layer here. This is what happens in your home. I.e. either 802.11 Wifi, or 802.3 ethernet.
Internet Layer#
At this point, DNS and HTTP come together. The IPv4 Internet Layer protocol only works with 32bit numbers as addresses.
But humans are pretty bad at remembering 32bit numbers, so instead we use hostnames. Often names, or actual words in our natural language.
As we’ve seen earlier, DNS is used by computers to convert the name to an IP address (the 32bit number).
Transport Layer#
This is the TCP we ignored earlier, and will continue to ignore.
When we take a look at DNS, it’s UDP, which we’ll also ignore.
Application Layer#
This describes HTTP resp. DNS. And later we’ll talk about HTTPS.
Methods to Filter#
At this point we have enough understanding to take a better look at how we can employer filters if we want to.
As network operator, we have the ability to see, modify or suppress anything that happens on the network.
Employing filters on different layers provides different tradeoffs.
Application Layer (HTTP)#
At this level, any entity between the client and the server can selectively deny requests for individual resources.
I.e. if we wanted to disallow specific things like a singular youtube video, or a specific social media post, this can be done.
To allow for introspection of this level (generally called Deep Package Inspection), the forwarder needs to analyze potentially high volume streams with full protocol decoders.
In the later section about countermeasures, we’ll see how this why this is not possible in every situation anymore, and why there’s other mechanisms used on the internet.
Application Layer (DNS)#
A widely used mechanism for blocking domains (i.e. everything with the same hostname) is DNS based block lists.
I.e. when a computer asks for the IP address by name, the server tells the client that this name does not have a name attached. Or gives it a false IP address of an attacker controlled server that provides some filtered answer.
In general, computers are configured to trust their network provider’s DNS server. I.e. your computer asks your router, your router then asks your ISP’s DNS server.
This makes it easy to filter DNS in practice. Since the computer is already nice enough to ask a server the network operator controls. And even when it isn’t, it’s a very simple protocol from the early days of the internet without cryptographic verification and can be intercepted with a single firewall rule.
Internet Layer#
Additionally, the simplest firewall settings can be applied on the internet layer. I.e. they don’t try to understand what hostnames or specific requests are at all, but filter based on lists of IP addresses.
This has multiple downsides. While it’s easy to configure in most systems and generally reduces the resource need of the network, the filter is on a different level than what should be filtered.
This mismatch works both ways. Any website can be on any number of IP addresses, and any single IP address can host any number of websites.
The host header in the HTTP request earlier Host: www.google.com tells the server which page to serve.
Countermeasures#
While all the filter mechanisms are used to some degree, there’s also countermeasures to the filters in place to allow people to avoid censorship, and preserve their privacy.
Each filter method can be prevented by a specific countermeasure. Though some countermeasure products (like well done VPNs) will prevent multiple types of filters.
HTTPS#
To prevent any forwarding entity to interfere with HTTP level mechanisms, HTTPS can be used.
It adds a layer of encryption to the communication, which prevents interceptors from reading or modifying both requests and responses.
We can look at the traffic in wireshark again. The overview is pretty similar to the HTTP case, but instead of HTTP the inner most protocol we see is TLS 1.3.
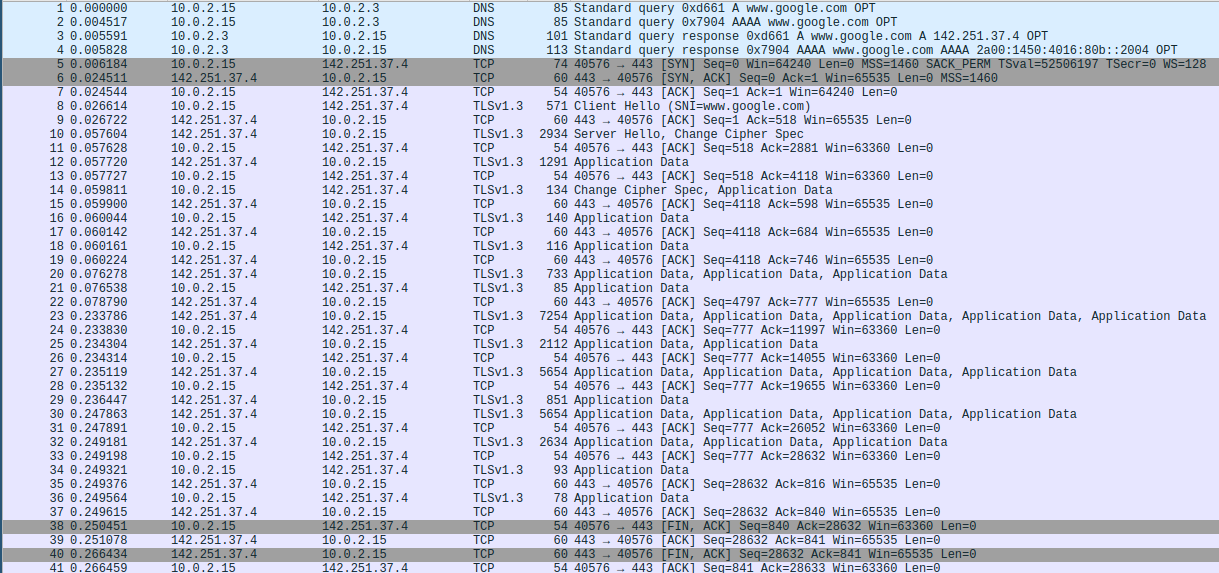
This is exactly the intent of the encryption layer in HTTPS.
Any watchers will not be able to read the content but only see the layer of encryption.
This is also obvious when we take a closer look at the contents of the TCP stream.

Instead of readable HTTP traffic, all we see is a jumbled mess.
With a binary analysis tool, we might be able to detect some structure (TLS) in there, but none of the contents.
Make a mental note about the highlighted www.google.com though, as we’ll take a closer look at that in the countercountermeasures.
DNS#
For DNS, there’s different types of countermeasures we can take.
From a simple imperfect one, to more advanced ones that re-use protective features of HTTPS.
Just use a Different Server#
The simplest way is to just not trust the ISP configured DNS server. This can be configured even on most consumer grade hardware.
There’s various servers provided by “friendly” organizations. Friendly in quotation marks, because it’s the likes of Google and Cloudflare that might be altruistic, or might have some self serving reasons.
Some examples
- Google: 8.8.8.8 / 8.8.4.4
- Cloudflare: 1.1.1.1
- quad9: 9.9.9.9
This can circumvent the laziest of DNS blocking, but can easily be redirected to the adversarial DNS servers with simple firewall rules.
DNSSEC#
As I mentioned earlier, part of why it is so easy to intercept and modify DNS is the lack of encryption. When a resolver with support for DNSSEC is used, it can detect modified responses. While this allows you to detect attempts to trick your computer into connecting to the wrong server, it will not allow any queries to succeed that the intercepting entity wants to fail.
It also doesn’t protect against the interceptor reading your requests and responses. Which will be relevant in the countercountermeasures.
DoT/DoH#
If you need to actually bypass well done DNS based filter methods it’s necessary to hide the DNS request from the interceptor.
Newer standards that realize this simple truth and packaged the same semantics (name to IP) in a new protocol.
Either similar to the original but in TCP and TLS (like HTTPS) or a novel one inside an HTTPS protocol.
This necessarily uses different servers, and adds protection from simple redirection to adversarial servers.
Internet Layer#
This type of filter is the hardest to avoid. Since it applies at the fundamentals of how any connection reaches a server the only way to avoid this is to never connect to the server.
Or rather, never connect to the server from your own client.
There’s different methods to do this.
This can be done via a simple HTTP proxy.
This is also the basics of how VPNs work. While there is still a virtual connection from the client to the server, for the internet it’s from the VPN egress point to the server.
Countercountermeasures#
The previous section mentioned countermeasures to countermeasures multiple times.
So let’s talk about what can be done to dig through the protection layers we’ve added above.
Breaking HTTPS#
While there are various attacks that can be used against older versions (or potentially with incredible amounts of resources) this section will only discuss what’s used in enterprise settings.
HTTPS generally uses PKI for authentication of the server and protection of the encryption secrets.
While this works reasonably well in the real world, when the client is under control of the interceptor as well, they can install a new root of trust into the system.
With this additional root, the client will trust the interceptors server.
This allows the interceptor to act as server and decrypt.
This allows to recreate the filters for HTTP.
Abusing SNI#
Previously when we had a quick look at the encrypted stream of HTTPS, there was a tiny bit of readable text.
To preserve the ability of a single server hosting multiple websites, the HTTPS standard slightly breaks layering assumptions and adds the hostname in an unencrypted bit.
An interceptor can abuse this, to filter connections. While they cannot read the contents or mess with them, they can still prevent the connection. Which is likely good enough for filters.
Counter Counter Counter Measure#
Yes. With every layer of countermeasure added by either side, another layer of countermeasure by the other side will be added.
ECH as a layer of encryption that’s per IP to encrypt the information required to setup the encryption per website.
No More VPNs!#
One of the countermeasures I mentioned before is either a proxy server, or a VPN. So obviously there are ways to prevent that as well.
The general approach to this dilemma is to block VPNs as well. See this entire article about how to do that.